
Home
Technical Blog
Publications
CV
Music
GitHub
About:
I am Jackson Vanover. I received my Ph.D. in Computer Science from UC Davis where I researched practical tools for testing and tuning numerical code.
Contact:
jacksonvanover [at] gmail [dot] com
Why does BLIS SGEMM shatter my roofline?
(or, "Cache Rules Everything Around Me")
Last Updated: December 02, 2025
DISCUSSED: questionably memory-bound matmuls, warm vs cold caches, Agner Fog's meticulously constructed instruction tables, my trash test system, grad student email listservs
During grad school at UC Davis, I spent a lot of time with students from the various ecology departments who introduced me to a strange and wonderful mailing list called eco-social through which I acquired a desktop tower for dirt cheap. My only goal with such a system was to have a personal machine at my house that I could SSH to for development. It has served its purpose well! In fact, it is the machine I used to perform all of the experiments for the EXCVATE paper.
How fast can this thing execute SGEMM?
To get an idea of what’s possible on this trash test system, let’s benchmark the BLIS implementation of SGEMM and compare its performance to the machine’s roofline model.
Benchmarking BLIS SGEMM performance
We are considering the operation \(C=AB+C\) with \(C \in \mathbb{F}^{m \times n}, A \in \mathbb{F}^{m \times k}, B \in \mathbb{F}^{k \times n}\) where \(\mathbb{F}\) is the set of 32-bit floating-point numbers.
Compiling BLIS: We compile for the sandybridge architecture for which BLIS has a pre-configured multithreaded build.
Spanning shapes and sizes: We run the BLIS implementation of SGEMM spanning different shapes and sizes per the following pseudo code:
int min_dim = 16;
int max_dim = 1024;
for ( int m = min_dim; m < max_dim; m = 2*m ){
for ( int n = min_dim; n < max_dim; n = 2*n ){
for ( int k = min_dim; k < max_dim; k = 2*k ){
...
}
}
}
Measuring performance: For each parameterization of SGEMM, we measure the FLOPs/second using \(\frac{2mnk}{t}\) where \(t\) is the minimum execution time in seconds over 10 executions; this is intended to account for run-to-run performance variability and to exclude any outliers due to cold caches. Subsequent multiplication by \(10^{-9}\) gives us GFLOPs/second.
Calculating arithmetic intensity: We calculate arithmetic intensity by dividing the GFLOPS/second measured above by \(4(2mn + mk + kn)\), i.e., \(2mn\) reads/writes of C, \(mk\) reads of A, \(kn\) reads of B, and each element is a 4 byte float.
Initializing the A and B matrices: Elements of A and B are initialized with values drawn from \(U(0,1)\).
Additional Information: To get an idea of how “rectangular” the matmul is, we will also measure the maximum dimension ratio. If m=k=n (all matrices are square), this quantity will be 1. If m=1, k=2, and n=3, this quantity will be 3.
Deriving the roofline for my test machine
The theoretical peak performance of the i7-3770K processor (measured in GFLOPs/second) can be calculated according to (Processor Frequency in GHz) x (# of Operations per cycle) x (# of Operands per Register) x (# of Physical Cores). The details below come from the output of lscpu and from Agner Fog’s instruction tables.
- The processor frequency is 3.5 GHz, or 3.9 GHz with Turbo Boost.
- The processor does not support FMA. The reciprocal throughput of single precision addition and multiplication instructions (ADDSS/ADDPS/VADDSS/VADDPS and MULSS/MULPS/VMULSS/VMULPS) is 1. This means that a new instruction can start executing 1 clock cycle after a previous instruction, assuming the values of its operands are not dependent on any previous instructions in the pipeline. The processor has separate execution ports for addition and multiplication instructions so an independent pair may be executed during the same clock cycle. → # of operations per cycle is 2.
- The processor has 256-bit-wide vector registers → # of Operands per Register is 256/32 = 8.
- The processor has 4 physical cores.
→Plugging these values in yields a peak GFLOPs/second of 224 or 249.6 with Turbo Boost.
The theoretical peak memory bandwidth (measured in GB/second) can be calculated according to (Memory Bus Width in Bytes) x (Memory Transfer Rate in MT/second) x (# active channels) / 1000. The details below come from the output of dmidecode -t memory:
- The memory bus width is 8 bytes.
- The memory transfer rate is 1333 MT/second.
- The memory is dual-channel.
→Plugging these values in yields a peak memory bandwidth of 21.328 GB/second.
An anomaly appears
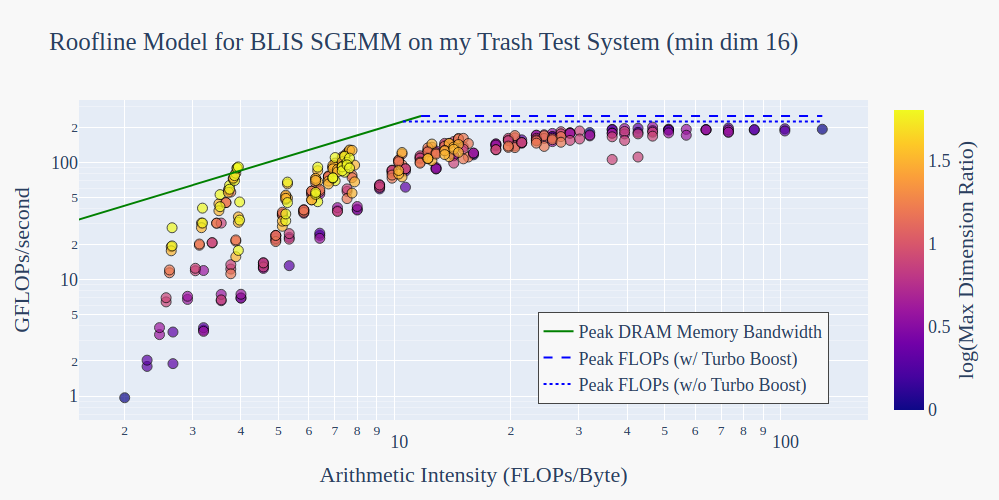 Why do some parameterizations of BLIS SGEMM surpass the theoretical memory bound?
Why do some parameterizations of BLIS SGEMM surpass the theoretical memory bound?
From the color of the markers, we can see these are rectangular GEMMs. Zooming in, there are three offenders. Described as (m,k,n) tuples, they are:
( 512, 16, 1024)
(1024, 16, 512)
(1024, 16, 1024)
Since the analogous rectangular GEMM for the next largest size of k – the tuple (1024, 32, 1024) – is below the roofline, let’s gather more data by looking at smaller sizes of k.
After generating more data, patterns emerge
Lowering the min_dim to 2 and rerunning our experiments, patterns emerge for memory-bound GEMMs:
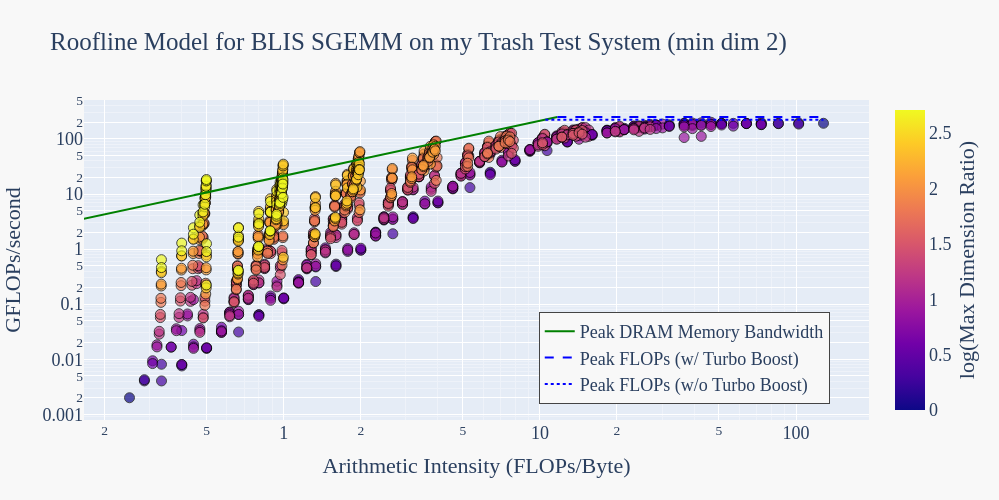 Now our offenders are:
Now our offenders are:
(1024, 2, 1024) (1024, 4, 1024) (1024, 8, 1024) (1024, 16, 1024)
( 512, 2, 1024) ( 512, 4, 1024) ( 512, 8, 1024) ( 512, 16, 1024)
(1024, 2, 512) (1024, 4, 512) (1024, 8, 512) (1024, 16, 512)
( 512, 2, 512) ( 512, 4, 512) ( 512, 8, 512)
( 256, 2, 1024) ( 256, 4, 1024) ( 256, 8, 1024)
( 256, 2, 512) ( 256, 4, 512) ( 256, 8, 512)
( 512, 2, 256) ( 512, 4, 256) ( 512, 8, 256)
(1024, 2, 256) (1024, 4, 256)
I feel confident in the theoretical memory bound that I calculated. However, upon reflection, I realize that this bound is derived from the bandwidth of the DRAM moving data into the last level cache, not to the actual arithmetic unit. Therefore, the “issue” I am observing likely stems from the fact that cache memory is faster than DRAM. Let’s test this.
Controlling for cache behavior
To control for cache behavior, we will execute each GEMM with a cold cache. Before each GEMM execution, we will allocate a buffer that exceeds the capacity of our 8 MiB Last-Level Cache and loop over the elements of that buffer with some trivial read or write. If we wanted more performant flushing, we could be more precise about the alignment of the buffer and divide it up into cache lines so that we only touch one element per cache line, but this will suffice for now. Rerunning our experiments, we get the following:
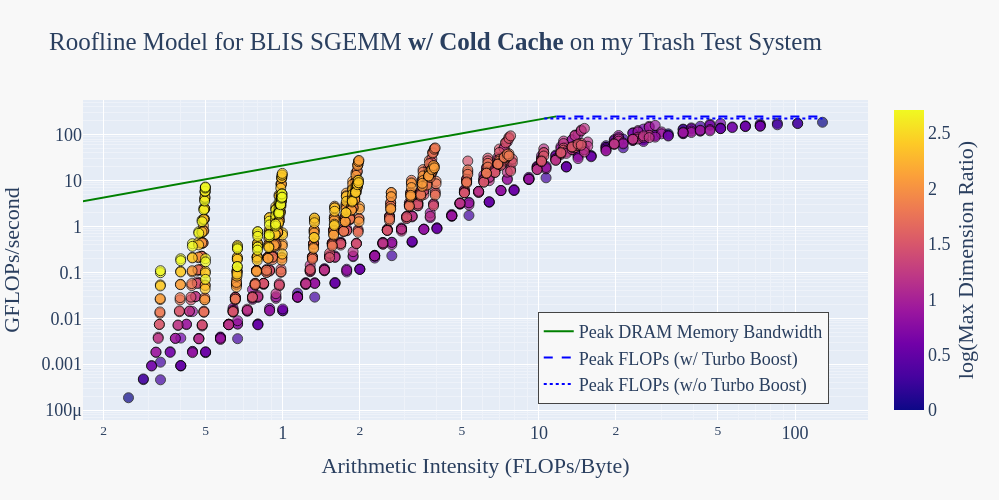 It looks like we’ve found our culprit!
It looks like we’ve found our culprit!
Naive Roofline → Cache-aware Roofline
Looking into this led me to a 2014 paper called “Cache-aware Roofline model: Upgrading the loft“. In that work, the authors point out that the original formulation for the roofline model misses a key aspect of modern applications and architectures which rely on the on-chip memory hierarchy: the calculated DRAM memory bandwidth only accurately describes the behavior of moving data from the DRAM to the Lowest Level Cache (LLC). In reality, the highest memory bound is actually set by the peak L1-to-Execution Unit bandwidth.
Fun bonus: the “Upgrading the Loft” paper is dated enough that they even construct and experimentally validate a cache-aware roofline model using the same i7-3770K processor as my Trash Test System! Taking the numbers from that paper, let’s plot the SGEMM executions with a warm cache using an extended, cache-aware roofline model:
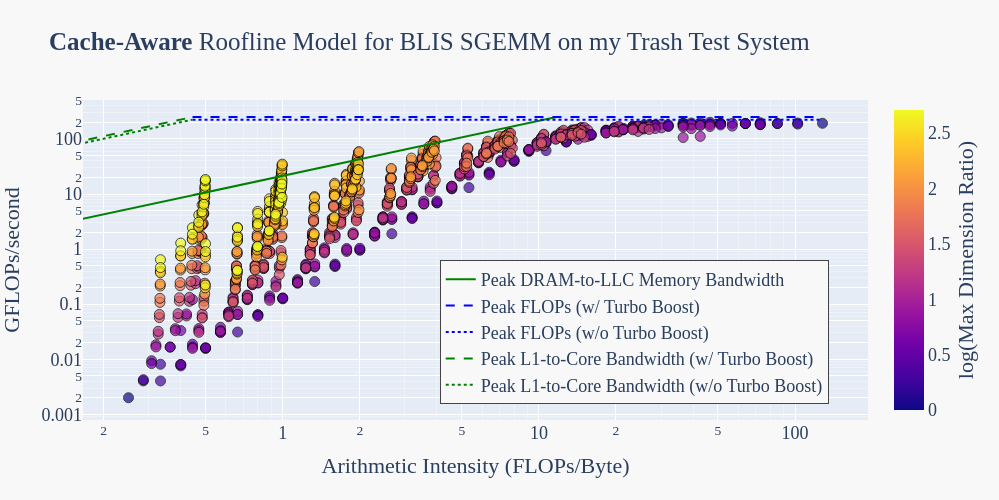 Now, courtesy of the “upgraded loft”, our roof is no longer “shattered” by BLIS SGEMM.
Now, courtesy of the “upgraded loft”, our roof is no longer “shattered” by BLIS SGEMM.
Lingering Questions (for future blog posts?)
- Which of these GEMMs benefits the most from cache behavior?
- According to the cache-aware roofline model, some of the GEMMs that were originally classified as memory-bound by the naive model are in fact computation-bound and it looks as though there is a huge gap of performance left on the table. What are the challenges to bringing these GEMMs closer to peak FLOPs? I have some suspicions (not enough data is moved to achieve peak streaming bandwidth, BLIS packs panels of A and B into contiguous temporary buffers which may be repacked on each iteration, constant overhead from non-arithmetic instructions probably dominates in small GEMMs, etc…) but I would like to look into this more thoroughly.