
Home
Technical Blog
Publications
CV
Music
GitHub
About:
I am Jackson Vanover. I received my Ph.D. in Computer Science from UC Davis where I researched practical tools for testing and tuning numerical code.
Contact:
jacksonvanover [at] gmail [dot] com
(Mis)understanding NVIDIA's ESC calculation
Last Updated: December 03, 2025DISCUSSED: Ozaki-style emulation of DGEMM, Hadamard products, "Productization", FP64 dynamic range, implicit bits made explicit, my confusion
(Note: On 01/12/26, I published a short update post clarifying what went wrong! After making a pass over this, be sure to check it out.)
Up for investigation: NVIDIA’s deployment of “Ozaki-style emulation” described in this newly-posted preprint.
This “Ozaki-style” emulation of an FP64 matrix product \(C = AB\) relies on a decomposition of each element of each operand into a sum of scaled INT8 values. Succinctly put, the number of INT8 slices used to represent the FP64 values is a parameter that controls the performance/precision tradeoff of the emulation, and NVIDIA has implemented a means of adaptively and conservatively setting this parameter based on the input data which, along with a native FP64 fallback, guarantees results with FP64 precision. In past talks like this one from this year’s BLIS retreat, I have heard them describe this as a “productization” of the algorithm.
Their strategy is based on something they call Exponent Span Capacity, or ESC. At a high level, the intuition makes sense to me: based on the dynamic range present in the DGEMM inputs, determine how many INT8 slices are required to maintain FP64 precision and use this as the basis for a decision procedure that determines whether or not to dispatch the emulation. With the release of the preprint, I am taking the opportunity to dive in and try to develop a deeper understanding of how they do this. In the back of my mind is a comment made by Harun Bayraktar, Senior Director of Math Libraries at NVIDIA, while speaking on this very topic at DMML70 a couple of months back. At that workshop, he mentioned that the algorithm overestimates the required precision by something on the order of 10% and asked a room full of numerical linear algebra folks to please come up with a better way.
This post will not describe a better way. In fact, in walking through the calculations from the paper, I find myself confused by the results. Follow along. And tell me what I am doing incorrectly if you happen to know!
NVIDIA’s Exponent Span Capacity (ESC) Calculation
A matrix product \(C=AB\) can be computed as a series of independent dot products, \(\mathbf{x} \cdot \mathbf{y}\) where \(\mathbf{x}\) is a row vector of \(A\) and \(\mathbf{y}\) is a column vector of \(B\). Moreover, each dot product can be computed as a Hadamard product \(\mathbf{x} \odot \mathbf{y} = \mathbf{z}\) followed by a reduction sum of \(\mathbf{z}\). It is this Hadamard product on which the ESC calculation is performed.
The goal of the ESC calculation is to estimate the number of extra bits needed to achieve FP64 accuracy for the dot product. The inputs to the calculation are the exponents of the maximum elements of \(\mathbf{x}\), \(\mathbf{y}\), and \(\mathbf{z}\). Denote these as \(exp(max(\mathbf{w}))\) for \(\mathbf{w} \in \{\mathbf{x}, \mathbf{y}, \mathbf{z}\}\). The calculation is simple:
ESC is then incremented by 1 to provide a margin of safety for the case in which the product of two scalars’ significands leads to a carry.
The paper goes on to discuss a sound and efficient estimation strategy for the exact ESC, but this will suffice for now.
My attempt to use ESC on a simple example fails
Consider the following dot product:
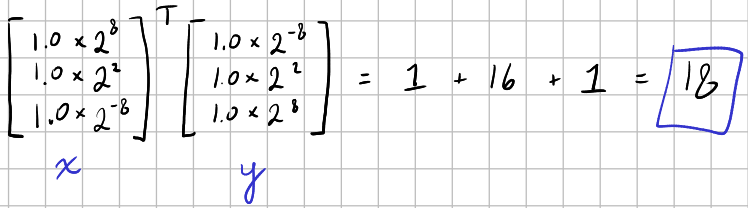
Here is the corresponding Hadamard product:
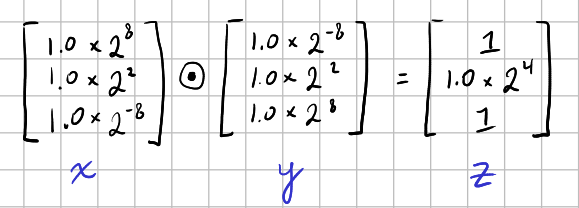
Now, ESC = 8 + 8 - 4 = 12, and the increment by 1 yields 13 required bits. Since each INT8 slice contributes 8 bits of precision, 13 bits of precision requires two INT8 slices per element, like so:
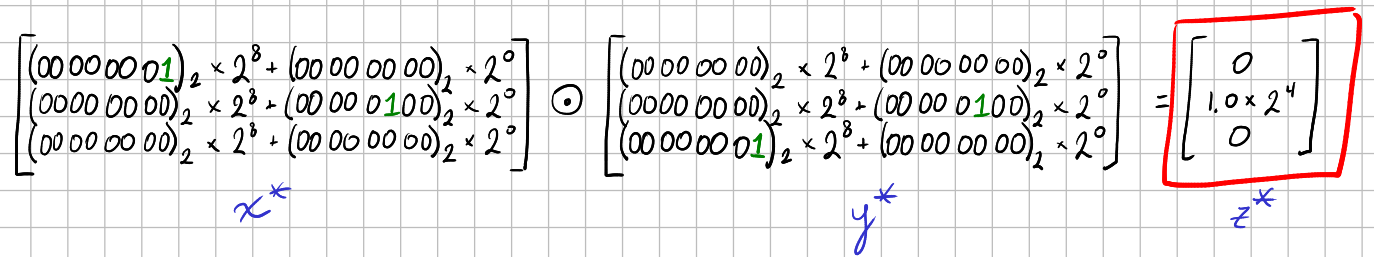 Here we see an issue: the \(1.0\times2^{-8}\) elements in \(\mathbf{x}\) and \(\mathbf{y}\) have been truncated to zero, yielding a Hadamard product with zeros where there should be ones and, ultimately, a dot product of 16 rather than 18.
Here we see an issue: the \(1.0\times2^{-8}\) elements in \(\mathbf{x}\) and \(\mathbf{y}\) have been truncated to zero, yielding a Hadamard product with zeros where there should be ones and, ultimately, a dot product of 16 rather than 18.
Note that this would still continue to be the case, regardless of the choice of scaling factors; if we had shifted all of the bits as far to the left as possible and used the scaling factors \(2^1\) and \(2^{-7}\), we would still not be able to represent \(1.0\times 2^{-8}\) with two INT8 slices.
For comparison, let’s derive what a full-fidelity representation of all values requires:
The largest exponent across all values is 8. The smallest is -8. The significands of all values are zero with an implicit leading one. So, we need (8+8) bits to cover the exponent range and we need 1 additional bit to represent the significand since we must make the implicit bit explicit. That makes for 17 bits, requiring three INT8 slices per element:

The failure appears to be consistent with the motivation behind ESC
In plain language, the motivation behind the ESC calculation is that it is supposed to ensure that the largest contribution to the dot product (i.e., the largest element of \(\mathbf{z}\)) is captured with full fidelity.
How is that captured in the calculation? The exponent of the maximum element of \(\mathbf{z}\) is the sum of the exponent of some element of \(\mathbf{x}\) and the exponent of some element in \(\mathbf{y}\). The ESC algorithm assumes maximal “skew” in the exponents of these two elements by assuming that the largest element in \(\mathbf{x}\) (respectively, \(\mathbf{y}\)) might be a factor of the largest element of \(\mathbf{z}\) and reasoning about what the corresponding factor from \(\mathbf{y}\) (respectively, \(\mathbf{x}\)) would be.
For the example: if the maximum element from \(\mathbf{x}\) (respectively, \(\mathbf{y}\)), having an exponent of 8, is a factor of the maximum element of \(\mathbf{z}\), having an exponent of 4, then the corresponding factor from \(\mathbf{y}\) (respectively, \(\mathbf{x}\)) must have an exponent of 4-8=-4. This does indeed preserve the full fidelity of the largest element of \(\mathbf{z}\) in the example: \(\mathbf{z}^*\) still contains \(1.0\times 2^{4}\).
Short Dialogue
Why bother with this assumption of maximal skew? If we are already making a pass over all of the exponent fields of all of the elements, can’t we just note the exponents of the factors from \(\mathbf{x}\) and \(\mathbf{y}\) that yield the largest exponent in \(\mathbf{z}\)?
The assumption of maximal “skew” has two benefits. First and most crucially, it obviates the need to track indices which would likely make the ESC calculation prohibitively slow. Second, it does so while covering the case in which multiple elements of \(\mathbf{z}\) share the same maximal exponent.
OK, but let’s back up; why even focus on the largest exponent in \(\mathbf{z}\)? Assuming that you applied the ESC calculation correctly to the example, such a focus led to a dot product with a relative error of \((18-16)/18 = 0.\bar{1}\) which is clearly unacceptable for such a trivial example. If you want to capture FP64 accuracy, why not use the maximum and minimum exponent across all values to determine the number of slices?
Consider a spectrum with maximal performance on one end and maximal precision on the other end. At the most precise end, one could represent the entire dynamic range of FP64 with approximately 2100 bits of fixed-point precision (back-of-the-napkin calculation given in the paper). At the other end, zero digits of precision trivially gets you maximal performance. The ESC approach lies between these extremes. If I understand it correctly (and again, I may be totally missing the mark), then the aforementioned strategy using the maximum and minimum exponents across all values would land between ESC and full representation of the FP64 dynamic range: more accurate than ESC but possibly less performant. Perhaps the tradeoff is not worth it?