
Home
Technical Blog
Publications
CV
Music
GitHub
About:
I am Jackson Vanover. I received my Ph.D. in Computer Science from UC Davis where I researched practical tools for testing and tuning numerical code.
Contact:
jacksonvanover [at] gmail [dot] com
Grading the BLAS: Strassen vs Classical GEMM
Last Updated: December 23, 2025DISCUSSED: floating-point rounding error, reconstruction of sparsity patterns, construction of inputs that maximize the degree of failure, some basic combinatorics
At the 2024 BLIS retreat, Jim Demmel presented a slide deck titled “Grading the BLAS”. In a recently published preprint that I discussed a bit in a previous post, NVIDIA cited that work as well as “private communications”; these works informed the inputs used to evaluate NVIDIA’s deployment of the Ozaki scheme to emulate DGEMM on INT8 Tensor Cores. Following that NVIDIA paper, the BLAS working group has started to prioritize publishing a preprint on “Grading the BLAS” so the NVIDIA folks can update their citation to something a little more fleshed-out.
I have been helping out with this effort by writing test code to empirically verify that these cleverly-designed test inputs do what they are designed to do. Now, as is evident from the slides linked above, the descriptions of these inputs are pretty terse. The internal documents I am referencing are not much better. At the moment, justification for why the designs of these test matrices should indeed work is pretty much left up to the reader. So, in addition to conducting these experiments, I’ll also be diving into the theory behind the input design.
In this post, I’ll be addressing test inputs designed to discriminate between \(O(n^3)\) and Strassen-like GEMMs
Background: The Archetypal Strassen’s Algorithm
1 - Partition A, B, and C into equally-sized block matrices:
2 - Calculate seven intermediate matrix products:
3 - Combine these intermediate products to form the submatrices of C:
Test inputs with rows and columns of zeros present a problem for Strassen
Elements of A and B are uniformly distributed at random in some chosen interval. Randomly-chosen rows and columns of A and B respectively are set to zero. Accordingly, the corresponding rows and columns of C = A*B should also be zero. However, this should present a problem for Strassen-like algorithms.
Why?
I believe the issue arises in step (2). Though combining submatrices of A and B before multiplication allows Strassen to perform one fewer multiplication than classical \(O(n^3)\) GEMM, it can also destroy some of the sparsity patterns, thus making those intermediate products dense. Consequently, the expected elements of C only end up zero with Strassen if the combination of intermediate products in step (3) perfectly cancels. This is assured with exact arithmetic. Not so with floating-point arithmetic, where accumulated rounding errors in each intermediate product calculated from step (2) can get left behind after what would have been perfect cancellation of the exact terms in step (3).
Let’s verify this via experimentation.
Experiment Setup
- Inputs: A, B ~ U(0,1) with 25% of their rows/cols resp. randomly selected and zeroed
- Problem Sizes: 32, 64, 128, 256, 512, 1024, 2048
- Error Metric: counting total number of zeros in calculated C matrices across all problem sizes
- Tested Implementations:
- netlibBLAS
- BLIS
- OpenBLAS
- cuBLAS
- OZIMMU with automatically selected slice counts, average mantissa loss threshold of 0 bits
- naive 1-level Strassen that I implemented
Results
blis n_zeros: 2446528
netlibblas n_zeros: 2446528
openblas n_zeros: 2446528
ozimmu_auto_thresh0 n_zeros: 2446528
cublas n_zeros: 2446528
strassen n_zeros: 1685659
→ Works as expected!
If my understanding is correct, the likelihood of Strassen’s failure on these inputs should increase at higher dimensions
If explanation about the accumulation of floating-point rounding error is correct, then the likelihood of Strassen’s failure should increase as the dimension increases because, as the dimension grows, the number of floating-point operations grows, and the chances of rounding error derailing perfect cancellation grows. Let’s see!
Experiment Setup
- Inputs: As before; A, B ~ U(0,1) with 25% of their rows/cols resp. randomly selected and zeroed.
- Problem Sizes: 4, 8, 16, 32, 64, 128, 256, 512, 1024
- Correctness Metric: Percentage of zeros lost in the product
- Repeats: Regenerate A and B and rerun 20 times for each problem size
- Tested Implementation: naive 1-level Strassen that I implemented
Results
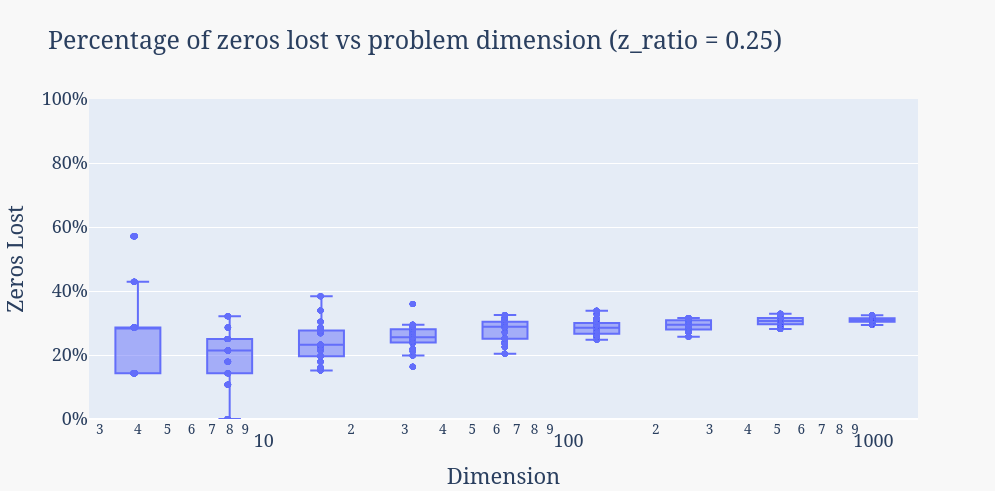
→ While not losing any zeros was unlikely across all dimensions (only one observed instance for dimension 8), higher dimensions appear to have a degree of failure that is more consistent, i.e., the variance of the number of zeros lost decreases as dimension increases.
→ With their higher variance, lower dimensions seem to offer the possibility of failing harder, i.e., more zeros lost.
But, as we will see shortly, the accumulation of floating-point rounding error induced by the randomly-selected input values turns out to be only half of the picture…
Can we maximize the number of zeros lost for this specific implementation?
In the plot above, the number of zeros lost appears to be slowly increasing as the dimension grows. But to test further by continuing to double the dimension while still doing 20x repeats would also test my poor machine and my poor patience. Let’s do a little theoretical work instead.
What’s the worst case with respect to the magnitude of failure?
In the non-recursive, 1-level Strassen I implemented, we can lose up to ~57% of the zeros given the perfect storm of rounding error and zero row/column placement…
According to my understanding, the problem for Strassen with these types of inputs stems from the destruction of sparsity in the intermediate products which necessitates perfect cancellation to reconstruct. Look closer at each of these products: not all portions of the expression on the right hand side always destroy sparsity. Restating the formulas for the intermediate products here, recalling that A has zero rows, B has zero columns, and inspecting which submatrices are combined via additions and subtractions, we can deduce the following:
Note that in my implementation, the multiplicative operation in each right-hand-side expression in not a recursive call to Strassen but a conventional \(O(n^3)\) GEMM. Combining this info with the formulas for the C submatrices…
…we can see that the diagonal blocks of C are the only ones at risk for losing zero entries in my 1-level Strassen implementation. This means that, for the worst case zero-loss, two events must coincide:
- The accumulation of floating-point rounding errors must actually hinder perfect cancellation and cause both diagonal blocks to lose all of their zeros.
- A distribution of zero rows and columns across A and B respectively such that the resulting C maximizes the number of zeros in the diagonal blocks while minimizing the number of zeros in the off-diagonal blocks.
Let’s look further into (2). The total number of zeros is given by the following:
To understand how I derived this formula: For the first term, note that \(z\) zero-rows will contain \(zn\) zeros, \(z\) zero-columns will contain \(zn\) zeroes, together this makes for \(2zn\) zeros. For the second term, note that the first term includes a double count of the overlap of the zero rows/columns which is of size \(z^2\); we must compensate with the subtraction.
Now, convince yourself as I did that half of each zero row and column must be in one of the diagonal blocks. Then, convince yourself that the maximum amount of possible zero loss can only be attained when the \(z^2\) overlapping zeros are in the off-diagonal blocks. In such a case, we can lose at most \(2zn/2 = zn\) zeros. We then get the following:
For my experiments with a z_ratio of 0.25, we find that we can lose at most 4/7 ~ 57% of the total zeros.
…but worst-case zero row/column placement is exceedingly unlikely
We only observed this worst case zero loss ratio once in the above plot: for the trace depicting the smallest GEMM of dimension 4. Why is this? We can answer this with some combinatorics.
Recall that for the worst-case zero-loss, we need the \(z^2\) overlapping zeros to be only in the off-diagonal blocks. Assume the zero rows/columns are selected randomly with uniform probability. Without loss of generality, say we select the zero-rows in A first. These \(z\) zero-rows in A must be all in the same half of A. If the top half of A contains the zero rows, then the \(z\) zero-columns in B must all be in the right half of B. Otherwise, the bottom half of A contains the zero rows and the \(z\) zero-columns in B must be all in the left half of B.
So: The first zero-row in A can be any of them. The remaining \(z-1\) zero-rows must then end up in the same half of A. Then, the next \(z\) zero-columns must all be in a specific half of B. Recalling that \(z = z\_ratio *n\), we can represent this as:
Which, evaluated at our chosen dimensions, gives us the following:
| n | P(worst-case selection of zero rows/columns) |
|---|---|
| \(4\) | \(0.5\) |
| \(8\) | \(0.091836735\) |
| \(16\) | \(0.0029585799\) |
| \(32\) | \(2.994305\times10^{-6}\) |
| \(64\) | \(3.027737\times10^{-12}\) |
| \(128\) | \(3.075682\times10^{-24}\) |
| \(256\) | \(3.163553\times10^{-48}\) |
| \(512\) | \(3.341457\times10^{-96}\) |
| \(1024\) | \(3.724809\times10^{-192}\) |
→ It is EXCEEDINGLY unlikely that random row and column selection would enable the worst-case zero-loss for any problems of reasonable size.
If we force worst-case zero row/column selection, we can more clearly see the negative effect of increased op counts on zero recovery via perfect cancellation
Experiment Setup
- Inputs: A, B ~ U(0,1) with worst-case zero row/column selection
- Problem Sizes: 4, 8, 16, 32, 64, 128, 256, 512, 1024
- Correctness Metric: Percentage of zeros lost in the product
- Repeats: Regenerate A and B and rerun 20 times for each problem size
- Tested Implementation: naive 1-level Strassen that I implemented
Results
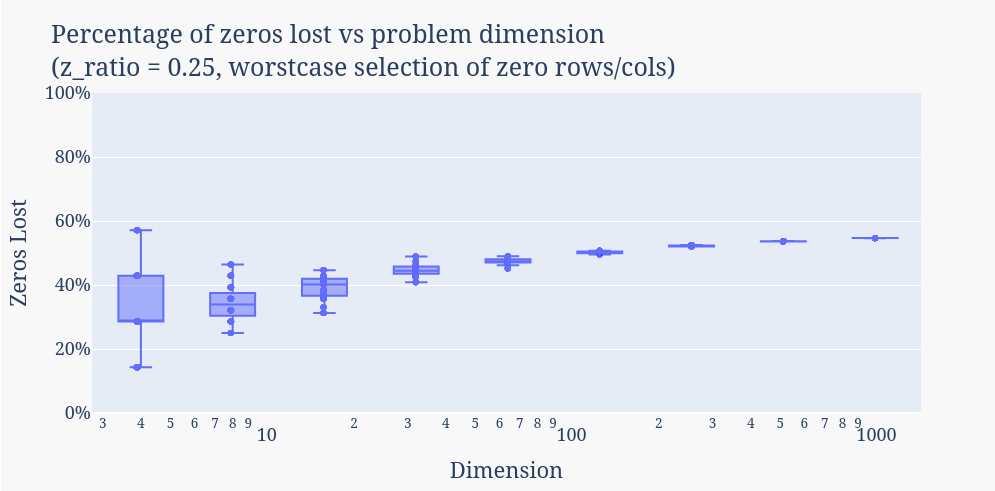
→ Now that we are controlling for the zero row/column selection, the only element of stochasticity here is floating-point rounding error that is induced by the randomly-selected elements of A and B. Consequently, as the dimension increases, not only does the variability decrease as in the first plot, but also the magnitude of failure converges to the maximum. This more accurately reflects the reasoning I proposed for why the probability of failure increases for higher dimensions (i.e, with more floating-point operations, increased likelihood of rounding errors negating perfect cancellation)
Practical recommendation for testing
The maximization of zero-loss above is overfit to my naive 1-level implementation of the archetypal Strassen algorithm. When the degree of recursion and the expressions for the intermediate products are unknown, our best bet of identifying Strassen-like algorithms is to place the rows and columns uniformly/randomly and to test larger problem sizes to increase the likelihood of floating-point rounding errors derailing the perfect cancellation required for zero recovery.